mongo迁移mysql总结
##1.分片解决的问题
##2.是否真的需要分片
在超大规模数据库需求的情况下,分片是唯一的途径。不只是对于MySQL,对大部分同类技术都是一样。
##3.分片的替代方案
功能分区
(概念同垂直切分)
复制
许多应用都是”读压力大”,而扩展读操作性要比扩展写要容易。这种情况,复制是很好的选择。
MYSQL自带的主从复制功能非常健壮,虽然其异步特性增加了应用的复杂性。这种情况下,开发人员必须根据客户对一致性的要求判断从哪台服务器读,不能从那读。缓存和队列
缓存抗读。许多系统应用缓存可以降低数据库读负载高达80-95%。(Redis,Memcached)
与之相对的是队列,他是优化写的。通过合并多次写操作,提高了对数据库操作的效率。(//todo Hbase mongo es)(AMQ,RabbitMQ)
大部分大型应用都应该重点考虑这两种技术。外部支持技术
高性能全文检索,考虑用ES,Solr。如果想做大规模数据分析,考虑应用Hadoop。
##4.分片之前的优化
硬件
如果你使用的数据库比较大,确保有大量内存和高性能闪存,许多情况下,它可以极大的提升系统。
Mysql版本和配置
最新的Mysql GA版本。它通常能提供额外的性能提升,能充分利用最新的硬件性能。
然后是合适的Mysql配置,配置是否最优可能导致甚至十倍的性能差距。查询、索引优化
##5.考虑分片
- 如果以上都不能让你获得满意的性能,那么我们考虑分片。
- 分片确实有使用低成本硬件或者更廉价的云实例获得潜在性能的优势。
- 分片之后同样可以使用主从复制来获得更高的可用性
###5.1 分片策略
分片层次:分片并不是必须在DB层面做的。许多应用(尤其是SAAS)经常在更高层次上做分片,
可以部署多套副本完全独立,每份副本有各自的分片Mysql环境。分片关键点:
1)要让尽可能多的数据访问点安排在一起,因为跨分片访问代价很昂贵(而且前提是支持的情况下)
2)分片之后的单片的读能力,数据承载能力是否能满足要求。
3)未来是否支持扩展(如分裂)分片的粒度:
按实例或者库分片,对库进行分片较灵活不必部署过多实例,且用库做分片比较容易做高可用集群,如A片主B片从部署到一台
服务器1,C从和A主到另一台2,B主C从到3,这样。分片技术:
1) Mycat
1)起因Cobar存在的一些比较严重的问题,及其使用限制。是基于开源cobar演变而来,我们对cobar的代码进行了彻底的重构。
2)使用NIO重构了网络模块,并且优化了Buffer内核,增强了聚合,Join等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。
3)1.4 版本以后 完全的脱离基本cobar内核,结合Mycat集群管理、自动扩容、智能优化,成为高性能的中间件。
Mycat本身是一个数据库中间件,实现了数据库代理、数据库引擎功能;
前端模拟MySQL协议与客户端交互,经过SQL解析器与后端通过MySQL协议、JDBC与各种关系型数据库交互;
与其他中间见不同的是,MyCAT后端兼容多个类型的数据库,且能实现跨库条件下大部分数据库函数。
2) cobar
1)随着业务的进行数据库的数据量和访问量的剧增,需要对数据进行水平拆分来降低单库的压力,而且需要高效且相对透明的来屏蔽掉水平拆分的细节。
2)为提高访问的可用性,数据源需要备份。
3)数据源可用性的检测和failover。
4)前台的高并发造成后台数据库连接数过多,降低了性能,怎么解决。
- 针对以上问题就有了cobar施展自己的空间了,cobar中间件以proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是mysql通信协议。将前台SQL语句变更并按照数据分布规则转发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。
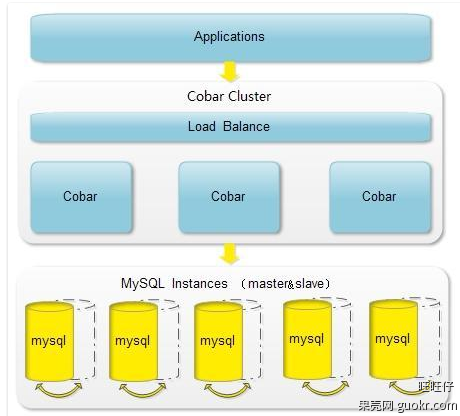
Cobar应用架构举例: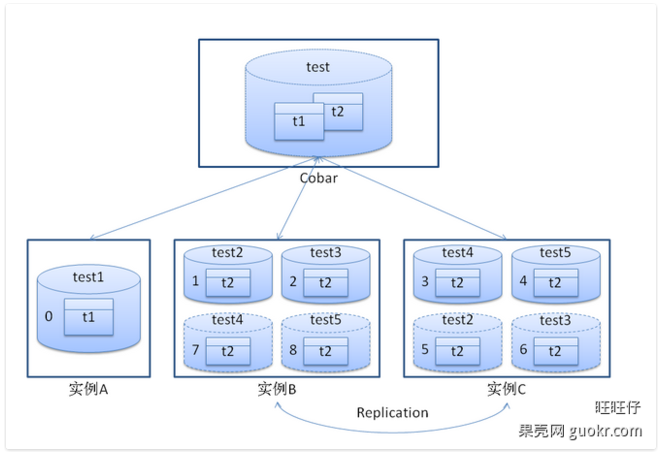
应用介绍:
- 1.通过Cobar提供一个名为test的数据库,其中包含t1,t2两张表。后台有3个MySQL实例(ip:port)为其提供服务,分别为:A,B,C。
- 2.期望t1表的数据放置在实例A中,t2表的数据水平拆成四份并在实例B和C中各自放两份。t2表的数据要具备HA功能,即B或者C实例其中一个出现故障,不影响使用且可提供完整的数据服务。
cobar优点总结:
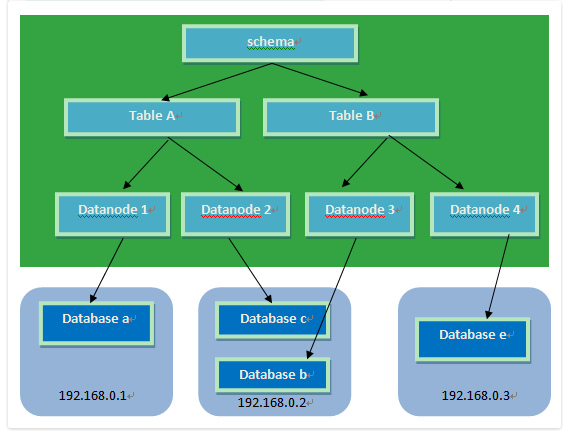
- 1.数据和访问从集中式改变为分布:
- (1)Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
- (2)Cobar也支持将不同的表放入不同的库
(3) 多数情况下,用户会将以上两种方式混合使用
注意!:Cobar不支持将一张表,例如test表拆分成test_1,test_2, test_3…..放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。
2.解决连接数过大的问题。
- 3.对业务代码侵入性少。
- 4.提供数据节点的failover,HA:
- (1)Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
- (2)Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步。
cobar缺点:
- 开源版本中数据库只支持mysql,并且不支持读写分离。
TDDL
- 淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中)
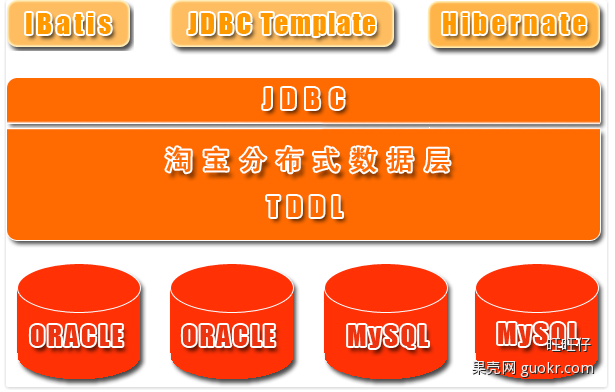
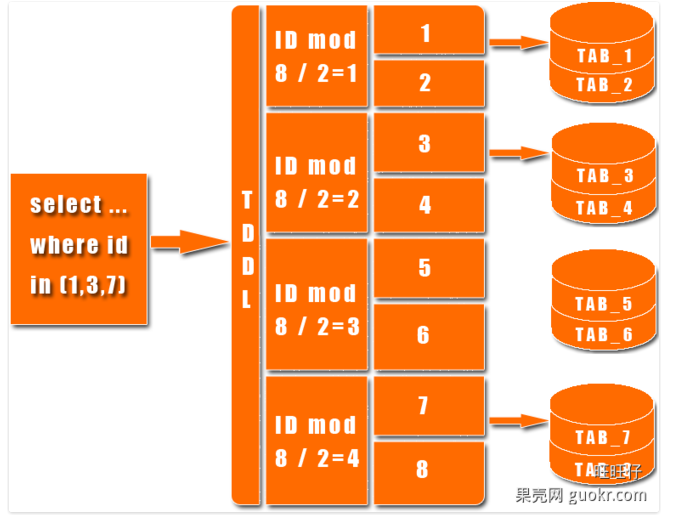
优点
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
缺点
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
终其所有,我们研究中间件的目的是使数据库实现性能的提高。具体使用哪种还要经过深入的研究,严谨的测试才可决定。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
MyCat
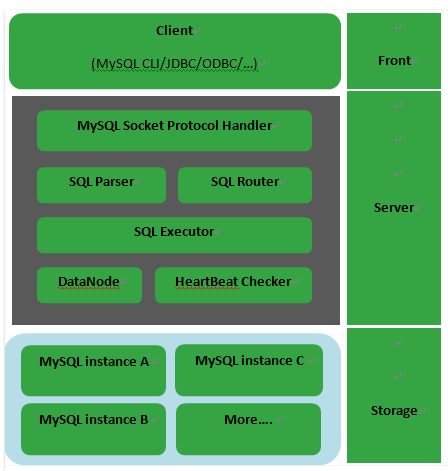
什么是MyCAT?简单的说,MyCAT就是: 一个彻底开源的,面向企业应用开发的“大数据库集群” 支持事务、ACID、可以替代Mysql的加强版数据库 ? 一个可以视为“Mysql”集群的企业级数据库,用来替代昂贵的Oracle集群 ? 一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server ? 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 ? 一个新颖的数据库中间件产品。
目标
低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
关键特性
支持 SQL 92标准 支持Mysql集群,可以作为Proxy使用 支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用 支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群,自动故障切换,高可用性 。
支持读写分离。
支持Mysql双主多从,以及一主多从的模式 。
支持全局表。
支持数据自动分片到多个节点,用于高效表关联查询 。
垮裤join,支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询多平台支持,部署和实施简单。
优势
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能,以及众多成熟的使用案例使得MyCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。广泛吸取业界优秀的开源项目和创新思路,将其融入到MyCAT的基因中,使得MyCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。MyCAT背后有一只强大的技术团队,其参与者都是5年以上资深软件工程师、架构师、DBA等,优秀的技术团队保证了MyCAT的产品质量。 MyCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设,目前在持续维护更新。
长期规划
在支持Mysql的基础上,后端增加更多的开源数据库和商业数据库的支持,包括原生支持PosteSQL、FireBird等开源数据库,以及通过JDBC等方式间接支持其他非开源的数据库如Oracle、DB2、SQL Server等实现更为智能的自我调节特性,如自动统计分析SQL,自动创建和调整索引,根据数据表的读写频率,自动优化缓存和备份策略等实现更全面的监控管理功能与HDFS集成,提供SQL命令,将数据库装入HDFS中并能够快速分析集成优秀的开源报表工具,使之具备一定的数据分析的能力。
jProxy
- JPROXY提供MariaDB, MySQL等数据库的统一接入访问,拥有流量过载保护,数据自动拆分,可配置路由规则,数据无缝迁移等功能。
应用场景:数据需要分库分表,自动扩容的应用。
架构图
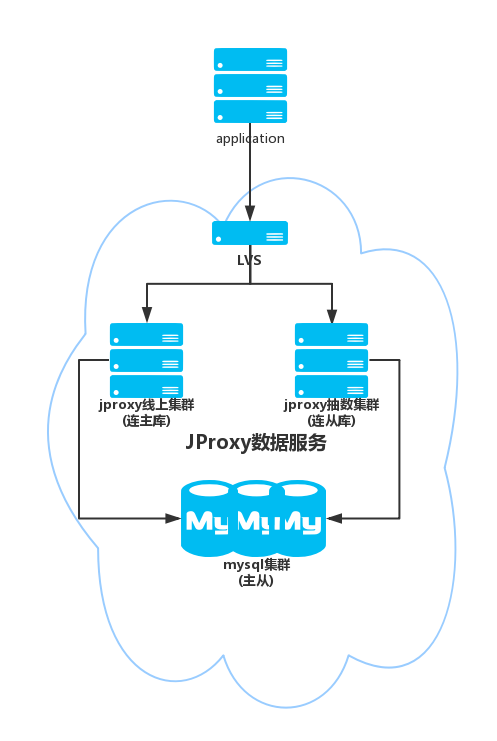
- JProxy: 连接应用程序与MySQL数据库的中间件,解决数据的存储、提高应用程序访问数据库的响应速度。
- Jmanager:数据库路由的管理中心,并同时提供路由信息的增删改等API操作。
- jtransfer: 自动化数据库迁移工具, 配合jmanager、jproxy、对后端数据库进行在线迁移。
jproxy 优化点
基于阿里cobar改造
- 性能调优
- Bug修复
- new feature
jproxy 实践
长sql 如 insert into tables values(…),(…)… 这样的语句若占有600左右kb,会导致proxy读却这个sql数据包很慢。
解决方案,将前端socket recivebuffer从默认值4k调整至128k后端实例连接池是以库为单位,当后端实例上有很多库时,连接数撑爆。
解决方案,改为以实例为单位jproxy线程数设置过大,导致mysql write超市,mysql关闭后端链接,导致jproxy read到EOF异常。
解决方案,将mysql write超时设置调高,并将jproxy execute线程数改小。
线上jproxy问题
原因 LVS 不恰当修改
需要更加熟悉JProxy提供的监控工具( http://jmonitor.xx.com/ )来第一时间掌握更多信息,以便和JProxy团队进行更高效的协作
另外jproxy要提供更可靠的服务
对应用来说,看到的是一个Big JProxy,它的具体实现包括核心的JProxy Server外,前端是LVS,后端是MySQL,现在这三部分都是不同的团队在运维的,当然是以JProxy团队为核心来协调的。
本次的排查过程中发现过一个现象: JProxy Server的连接数突增,但应用Application的访问量没有异常变化,这个也可以作为LVS变更引起的问题的一个辅证。
+———————————————————————–+
| |
| +—————+ |
| | | |
| +—–> | MySQL1 | |
| | | | |
+————+ | +————-+ +—————+ | +—————+ |
| | | | | | | | |
| Application +—-> | | LVS | +–> | JProxy +–+ |
| | | | | | Server | | +—————+ |
| | | | | | | | | | |
+————+ | +————-+ +—————+ +——> | MySQL2 | |
| | | |
| | | |
| +—————+ |
| |
| Big JProxy |
| |
+———————————————————————–+
海关迁移
目标
dms系统数据库从oralce迁移至mysql。
dms系统支持日均单量达到1亿。
dms系统数据库读写tp99<10毫秒。
迁移过程对业务无任何不良影响。
###
《常见问题及解决思路》
1)可用性,解决思路是冗余(复制)
2)读写比
2.1)读多些少:用从库,缓存,索引来提高读性能
2.2)业务层控制强制读主来解决从库不一致问题
2.3)双淘汰来解决缓存不一致问题
2.4)读写相近,写多读少:不要使用缓存,该怎么整怎么整
《拆库后业务实战》
1)不这么玩:联合查询、子查询、触发器、用户自定义函数、夸库事务
2)IN查询怎么玩
2.1)分发MR
2.2)拼装成不同SQL语句
3)非partition key查询怎么玩
3.1)定位一个库
3.2)分发MR
4)夸库分页怎么玩
4.1)修改sql语句,服务内排序
4.2)引入特殊id,减少返回数量
4.3)业务优化,禁止跨页查询,允许模糊查询